PostgreSQL Scalability: Towards Millions TPS
PostgreSQL scalability on multicore and multisocket machines became a subject of optimization long time ago once such machines became widely used. This blog post shows brief history of vertical scalability improvements between versions 8.0 and 8.4. PostgreSQL 9.2 had very noticeable scalability improvement. Thanks to fast path locking and other optimizations it becomes possible to achieve more than 350 000 TPS in select-only pgbench test. The latest stable release PostgreSQL 9.5 also contain significant scalability advancements including LWLock improvement which allows achieving about 400 000 TPS in select-only pgbench test.
Postgres Professional company also became involved into scalability optimization. In partnership with IBM we researched PostgreSQL scalability on modern Power8 servers. The results of this research was published in popular Russian blog habrahabr (Google translated version). As brief result of this research we identify two ways to improve PostgreSQL scalability on Power8:
- Implement Pin/UnpinBuffer() using CAS operations instead of buffer header spinlock;
- Optimize LWLockAttemptLock() in assembly to make fewer loops for changing lwlock state.
The optimization #1 appears to give huge benefit on big Intel servers as well, while optimization #2 is Power-specific. After long rounds of optimization, cleaning and testing #1 was finally committed by Andres Freund.
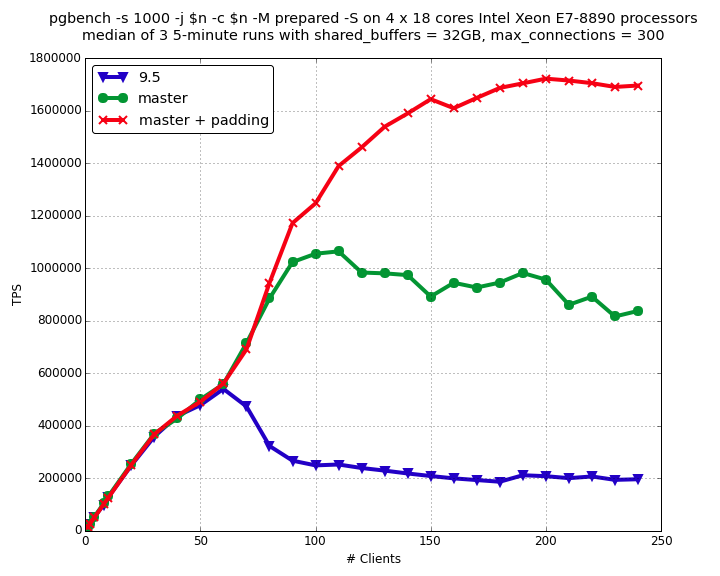
On the graph above, following PostgreSQL versions were compared:
- 9.5.2 release – peak is 540 000 TPS with 60 clients,
- 9.6 master (more precisely 59455018) – peak is 1 064 000 TPS with 110 clients,
- 9.6 master where all PGXACTs were full cacheline aligned – peak is 1 722 000 TPS with 200 clients.
Alignment issues worth some explanation. Initially, I complained performance regression introduced by commit 5364b357 which increases number of clog buffers. That was strange by itself, because read-only benchmark shouldn’t lookup to clog thanks to hint bits. As expected it appears that clog buffers don’t really affect read-only performance directly, 5364b357 just changed layout of shared memory structures.
It appears that read-only benchmark became very sensitive to layout of shared memory structures. As result performance has significant variety depending on shared_buffers, max_connections and other options which influence shared memory distribution. When I gave Andres access to that big machine, he very quickly find a way to take care about performance irregularity: make all PGXACTs full cacheline aligned. Without this patch SnapshotResetXmin() dirties processor cache containing multiple PGXACTs. With this patch SnapshotResetXmin() dirties cacheline with only single PGXACT. Thus, GetSnapshotData() have much less cache misses. That was surprising and good lesson for me. I knew that alignment influence performance, but I didn’t expect this influence to be so huge. PGXACT cacheline alignment issue was discovered after feature freeze for 9.6. That means it would be subject for 9.7 development. Nevertheless, 9.6 have very noticeable scalability improvement.
Therefore, PostgreSQL single instance delivers more than 1 million TPS and one could say, that PostgreSQL opens a new era of millions TPS.
P.S. I’d like to thank:
- Andres Freund, so-author and committer of patch;
- My PostgresPro colleagues: Dmitry Vasilyev who run a lot of benchmarks, YUriy Zhuravlev who wrote original proof of concept of this patch;
- Dilip Kumar and Robert Haas who helped with testing.