Pg_pathman UPDATE and DELETE Support and Benchmark
Recently pg_pathman receives support of UPDATE and DELETE queries. Because of some specialties of PostgreSQL query planner hooks, UPDATE and DELETE planning is accelerated only when only one partition is touched by query. Other way, regular slow inheritance query planning is used. However, case when UPDATE and DELETE touches only one partition seems to be most common and most needing optimization.
Also, I’d like to share some benchmark. This benchmark consists of operations on journal table with about 1 M records for year partitioned by day. For sure, this is kind of toy example, because nobody will split so small amount of data into so many partitions. But it is still good to see partitioning overhead. Performance of following operations was compared:
- Select single row by its timestamp,
- Select data for whole day (whole one partition),
- Insert one row with random timestamp,
- Update one row with random timestamp.
The following partitioning methods were compared:
- Single table, no partitioning,
- pg_partman extension,
- pg_pathman extension.
Benchmarks were done on 2 x Intel Xeon CPU X5675 @ 3.07GHz, 24 GB of memory server with fsync = off in 10 threads. See the results below.
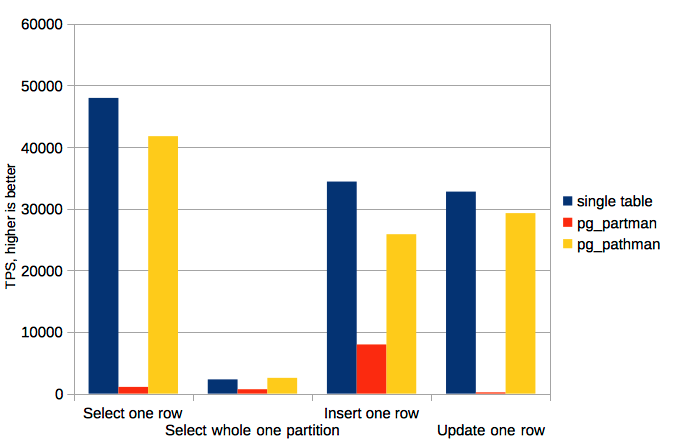
| Test name | single table, TPS | pg_partman, TPS | pg_pathman, TPS |
|---|---|---|---|
| Select one row | 47973 | 1084 | 41775 |
| Select whole one partition | 2302 | 704 | 2556 |
| Insert one row | 34401 | 7969 | 25859 |
| Update one row | 32769 | 202 | 29289 |
I can make following highlights for these results.
- pg_pathman is dramatically faster than pg_partman, because pg_pathman uses planner hooks for faster query planning while pg_partman uses built-in inheritance mechanism.
- When selecting or updating a single row, pg_pathman is almost as fast as plain table. The difference for insertion of single row is slightly bigger because trigger is used for that.
- The difference between pg_partman and pg_pathman when selecting the whole partition is not as dramatic as when selecting the one row. This is why planning time becomes less substantial in comparison with execution time.
- Inserting random rows with pg_pathman is still much faster than with pg_partman while both of them use trigger on parent relation. However, pg_pathman uses fast C-function for partition selection.
- Selecting the whole partition when table is partitioned by pg_pathman is slightly faster than selecting same rows from plain table. This is because sequential scan was used for selecting whole partition while index scan was used for selecting part of plain table. When among of data is big and doesn’t fit cache this difference is expected to be much more.
See this gist for SQL-scripts used for benchmarking.
- create_*.sql creates journal table using various partitioning methods.
- select_one.sql, select_day.sql, insert.sql and update.sql are pg_bench scripts.
P.S. This post is not a criticism of pg_partman. It was developed long time before extendability mechanisms which pg_pathman use were created. And it is a great extension which has served many years.