Dramatical Effect of LSE Instructions for PostgreSQL on Graviton2 Instances
The world changes. ARM architecture breaks into new areas of computing. An only decade ago, only your mobile, router, or another specialized device could be ARM-based, while your desktop and server were typically x86-based. Nowadays, your new MacBook is ARM-based, and your EC2 instance could be ARM as well.
In the mid-2020, Amazon made graviton2 instances publically available. The maximum number of CPU core there is 64. This number is where it becomes interesting to check PostgreSQL scalability. It’s exciting to check because ARM implements atomic operations using pair of load/store. So, in a sense, ARM is just like Power, where I’ve previously seen a significant effect of platform-specific atomics optimizations.
But on the other hand, ARM 8.1 defines a set of LSE instructions, which, in particular, provide the way to implement atomic operation in a single instruction (just like x86). What would be better: special optimization, which puts custom logic between load and store instructions, or just a simple loop of LSE CAS instructions? I’ve tried them both.
You can see the results of read-only and read-write pgbench on the graphs
below (details on experiments are here).
pg14-devel-lwlock-ldrex-strex is the patched PostgreSQL with special
load/store optimization for lwlock, pg14-devel-lse is PostgreSQL compiled
with LSE support enabled.
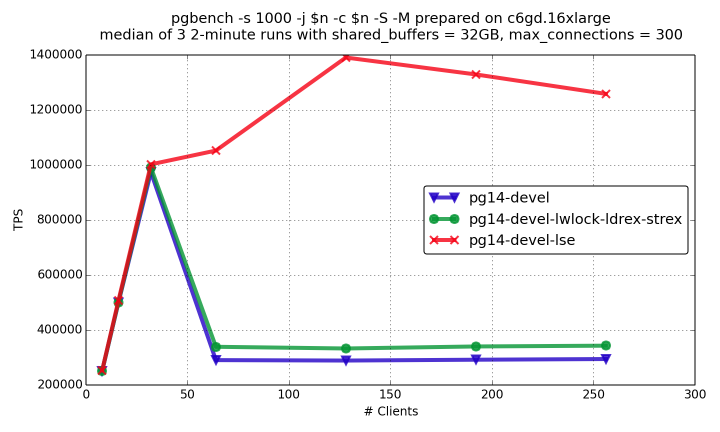
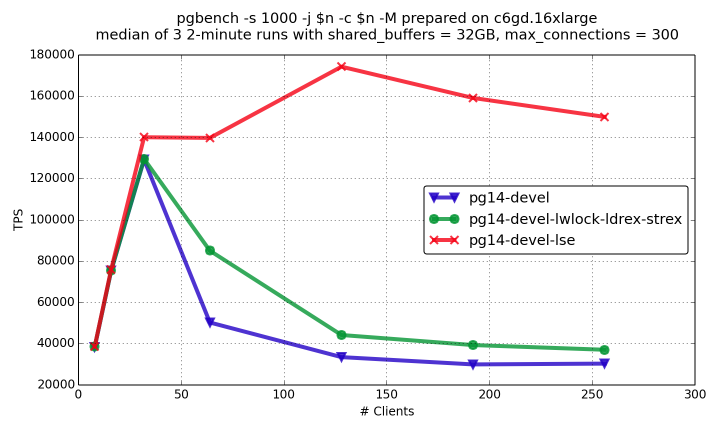
You can see that load/store optimization gives substantial positive effect, but LSE rocks here!
So, if you’re running PostgreSQL on graviton2 instance, make sure you’ve binaries compiled with LSE support (see the instruction) because the effect is dramatic.
BTW, it appears that none of these optimizations have a noticeable effect on the performance of Apple M1. Probably, M1 has a smart enough inner optimizer to recognize these different implementations to be equivalent. And it was surprising that LSE usage might give a small negative effect on Kunpeng 920. It was discouraging for me to know an ARM processor, where single instruction operation is slower than multiple instruction equivalent. Hopefully, processor architects would fix this in new Kunpeng processors.
In general, we see that now different ARM embodiments have different performance characteristics and different effects of optimizations. Hopefully, this is a problem of growth, and it will be overcome soon.
Update: As Krunal Bauskar pointer in the comments, LSE instructions are still faster than the load/store option on Kunpeng 920. Different timings might cause the regression. For instance, with LSE instructions, we could just faster reach the regression caused by another bottleneck.