PostgreSQL 14: Substantion Change to Fulltext Query Parsing

Long story short, since PostgreSQL 14 to_tsquery('pg_class') becomes
'pg' <-> 'class' instead of 'pg' & 'class'
(commit 0c4f355c6a). That is for instance,
in PostgreSQL 13 and earlier to_tsquery('pg_class') matches
to_tsvector('a class of pg'). But since PostgreSQL 14 it doesn’t match, but
still matches to_tsvector('pg_class') and to_tsvector('pg*class').
This is incompatible change, which affects fts users, but we have to do this
in order to fix phrase search design problems.
The story started with a
bug
when to_tsvector('pg_class pg') didn’t match to
websearch_to_tsquery('"pg_class pg"').
1 2 3 4 5 | |
Looks strange! Naturally, when you search for some
text in quotes, you expect it to match at least the exact same text in the document.
But it doesn’t. My first idea was that it’s just bug of websearch_to_tsquery()
function, but to_tsquery() appears to have the same problem:
to_tsquery('pg_class <-> pg') doesn’t match to to_tsvector('pg_class pg')
as well.
1 2 3 4 5 | |
I was surprised that although phrase search arrived many years ago, basic things don’t work.
Rainbow Your Psql Output
 It seems a good idea to change grey psql output to a lovely rainbow in honor
of IDAHOT day.
Thankfully there is lolcat utility,
which is very easy to install on Linux and Mac OS.
It seems a good idea to change grey psql output to a lovely rainbow in honor
of IDAHOT day.
Thankfully there is lolcat utility,
which is very easy to install on Linux and Mac OS.
Linux
1
| |
Mac OS
1
| |
Having lolcat installed, you can set it up as a psql pager and get lovely rainbow psql output!
1 2 | |
Jsonpath: ** Operator and Lax Mode Are't Meant to Be Together.
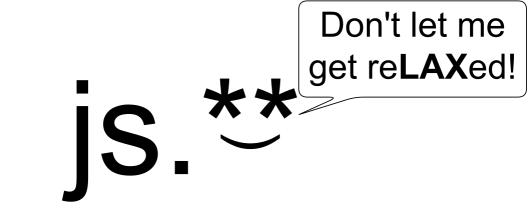
PostgreSQL has an extension to jsonpath: ** operator, which explores
arbitrary depth finding your values everywhere. At the same time, there is
a lax mode, defined by the standard, providing a “relaxed” way for working
with json. In the lax mode, accessors automatically unwrap arrays; missing
keys don’t trigger errors; etc. In short, it appears that the ** operator
and lax mode aren’t designed to be together :)
Dramatical Effect of LSE Instructions for PostgreSQL on Graviton2 Instances
The world changes. ARM architecture breaks into new areas of computing. An only decade ago, only your mobile, router, or another specialized device could be ARM-based, while your desktop and server were typically x86-based. Nowadays, your new MacBook is ARM-based, and your EC2 instance could be ARM as well.
In the mid-2020, Amazon made graviton2 instances publically available. The maximum number of CPU core there is 64. This number is where it becomes interesting to check PostgreSQL scalability. It’s exciting to check because ARM implements atomic operations using pair of load/store. So, in a sense, ARM is just like Power, where I’ve previously seen a significant effect of platform-specific atomics optimizations.
But on the other hand, ARM 8.1 defines a set of LSE instructions, which, in particular, provide the way to implement atomic operation in a single instruction (just like x86). What would be better: special optimization, which puts custom logic between load and store instructions, or just a simple loop of LSE CAS instructions? I’ve tried them both.
You can see the results of read-only and read-write pgbench on the graphs
below (details on experiments are here).
pg14-devel-lwlock-ldrex-strex is the patched PostgreSQL with special
load/store optimization for lwlock, pg14-devel-lse is PostgreSQL compiled
with LSE support enabled.
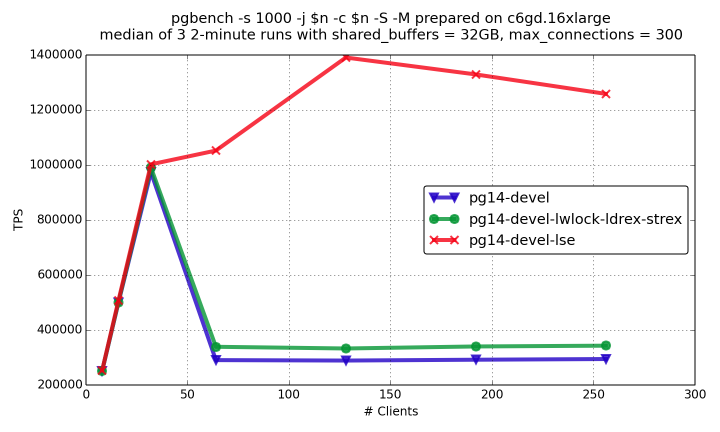
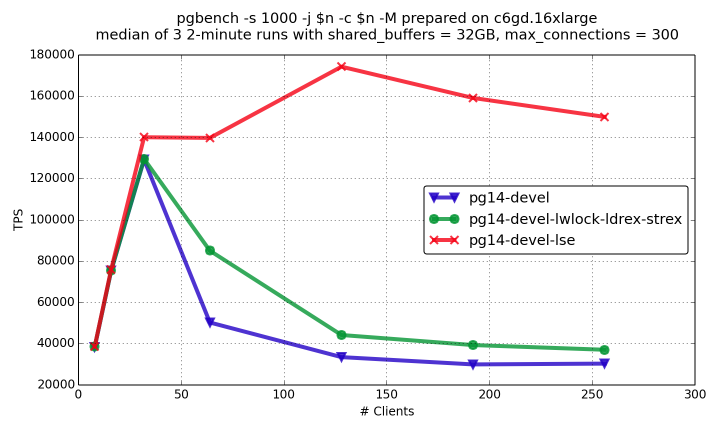
You can see that load/store optimization gives substantial positive effect, but LSE rocks here!
So, if you’re running PostgreSQL on graviton2 instance, make sure you’ve binaries compiled with LSE support (see the instruction) because the effect is dramatic.
BTW, it appears that none of these optimizations have a noticeable effect on the performance of Apple M1. Probably, M1 has a smart enough inner optimizer to recognize these different implementations to be equivalent. And it was surprising that LSE usage might give a small negative effect on Kunpeng 920. It was discouraging for me to know an ARM processor, where single instruction operation is slower than multiple instruction equivalent. Hopefully, processor architects would fix this in new Kunpeng processors.
In general, we see that now different ARM embodiments have different performance characteristics and different effects of optimizations. Hopefully, this is a problem of growth, and it will be overcome soon.
Update: As Krunal Bauskar pointer in the comments, LSE instructions are still faster than the load/store option on Kunpeng 920. Different timings might cause the regression. For instance, with LSE instructions, we could just faster reach the regression caused by another bottleneck.
Full Text Search Done (Almost) Right in PostgreSQL 11
Long story short, using PostgreSQL 11 with RUM index you can do both TOP-N query and COUNT(*) for non-selective FTS queries without fetching all the results from heap (that means much faster). Are you bored yet? If not, please read the detailed description below.
At November 1st 2017, Tome Lane committed a patch enabling bitmap scans to behave like index-only scan when possible. In particular, since PostgreSQL 11 COUNT(*) queries can be evaluated using bitmap scans without accessing heap when corresponding bit in visibility map is set. This patch was written by Alexander Kuzmenkov and reviewed by Alexey Chernyshov (sboth are my Postgres Pro colleagues), and it was heavily revised by Tom Lane.
ALTER INDEX ... SET STATISTICS ...???
It’s not very widely known, but PostgreSQL is gathering statistics for indexed expressions. See following example.
1 2 3 4 5 6 7 8 9 | |
We created table with two columns x and y whose values are independently and uniformly distributed from 0 to 1. Despite we analyze that table, PostgreSQL optimizer estimates selectivity of x + y < 0.01 qual as 1/3. You can see that this estimation is not even close to reality: we actually selected 56 rows instead of 333333 rows estimated. This estimation comes from a rough assumption that < operator selects 1/3 of rows unless something more precise is known. Of course, it could be possible for planner to do something better in this case. For instance, it could try to calculate histogram for x + y from the separate histograms for x and y. However, PostgreSQL optimizer doesn’t perform such costly and complex computations for now.
Situation changes once we define an index on x + y.
"Our Answer to Uber" Talk at United Dev Conf, Minsk
Today I gave a talk “Our answer to Uber” at United Dev Conf, Minsk. Slides could be found at slideshare. In my talk I attempted to make a review of Uber’s notes and summarize community efforts to overcome highlighted shortcomings.
United Dev Conf is quite big IT conference with more than 700 attendees. I’d like to notice that interest in PostgreSQL is quire high. The room was almost full during my talk. Also, after the talk I was continuously giving answers to surroundings in about 1 hour.
I think that Minsk is very attractive place for IT events. There are everything required for it: lovely places for events, good and not expensive hotels, developed infrastructure. Additionally Belarus introduces 5 days visa-free travel for 80 countries, and that made conference attendance much easier for many people. It would be nice to have PGDay.Minsk one day.
Faceted Search in the Single PostgreSQL Query
Faceted search is very popular buzzword nowadays. In short, faceted search specialty is that its results are organized per category. Popular search engines are receiving special support of faceted search.
Let’s see what PostgreSQL can do in this field. At first, let’s formalize our task. For each category which have matching documents we want to obtain:
- Total number of matching documents;
- TOP N matching documents.
For sure, it’s possible to query such data using multiple per category SQL queries. But we’ll make it in a single SQL query. That also would be faster in majority of cases. The query below implements faceted search over PostgreSQL mailing lists archives using window functions and CTE. Usage of window function is essential while CTE was used for better query readability.
RuntimeAppend in Pg_pathman: Achievements and New Challenges
Dealing with partitioned tables we can’t always select relevant partitions during query planning. Naturally, during query planning you can’t know values which come from subquery or outer part of nested loop join. Nevertheless, it would be ridiculous to scan all the partitions in such cases.
This is why my Postgres Professional colleague Dmitry Ivanov developed a new custom executor node for pg_pathman: RuntimeAppend. This node behaves like regular Append node: it contains set of children Nodes which should be appended. However, RuntimeAppend have one distinction: each run it selects only relevant children to append basing on parameter values.
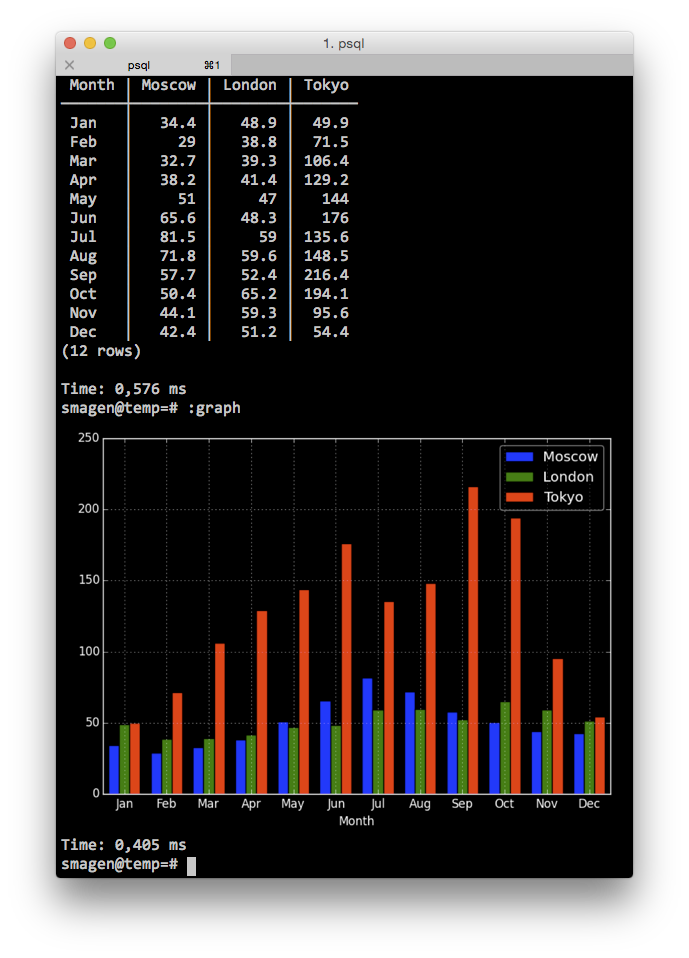
Drawing Graphs Directly in Psql
For people who are actively working with psql, it frequently happens that you want to draw graph for the table you’re currently seeing. Typically, it means a cycle of actions including: exporting data, importing it into graph drawing tool and drawing graph itself. It appears that this process could be automated: graph could be drawn by typing a single command directly in psql. See an example on the screenshot below.